7-Peat - Hacking 7 Power Companies
Introduction
This blog post will demonstrate how a low-hanging fruit discovered in a relatively unknown SaaS application used mainly by energy companies allowed an attacker to bypass the authentication and access sensitive (customer) data. Along with describing the attack itself, a few other points will be discussed regarding the challenges large organizations face within application security.
Motivation
Working application security at a large organization I’ve witnessed several challenges that many organizations face. With hundreds or even thousands of applications, it becomes daunting to not only keep track of which applications are exposed on the internet (looking at you Shadow-It) but also ranking the applications in a way that will prioritize the ones warranting a pentest. Regarding the first point about internet exposure, this led to the birth of the Attack Surface Management (ASM) market. A new mantra has been adopted by several of these ASM companies which essentially is “What you can’t see, can hurt you”.
Furthermore, with the rapid advancement in DevSecOps processes and tools, more and more low-hanging fruits are caught and mitigated during the development life cycle. As such when developing in-house applications, you have the ability to see the DevSecOps processes which are implemented and make any alterations that you see fit. However this now completely changes when purchasing software from a third-party vendor. As you lack the visibility on how the security phase within the vendor’s development lifecycle operates, you are only left with the choice of hoping it’s done correctly, let alone if it’s done at all.
As such several mature security teams have adopted a third-party risk management program (TPRM) which performs risk assessments and even pentests in some cases on vendor software. Because both manpower and time are finite resources, it becomes a challenge to prioritize these assessments and in the majority of cases software, particularly scanners are leveraged to perform the job. It has been pointed out several times in the past, vulnerability scanners are not a one-size-fits-all approach. If anything, a vulnerability scanner shouldn’t be finding anything if the DevSecOps pipeline is properly implemented.
As mentioned earlier, one of the challenges is developing a methodology to rank applications based on some index that will prioritize the ones that will warrant a pentest. From a quick overlook, it’s quite obvious that this specific index would be the risk the application poses. As such the DREAD & STRIDE threat modeling methodologies have been introduced. An example of this could be comparing two applications where one is dynamic, accessing sensitive data, and all in all, possessing a far bigger attack surface when compared to an application that just has a static page displaying the organization’s stock prices fetched from a third-party API. Based on this example it’s obvious that the first application would rank higher based on risk. While the comparison in the last example was obvious, it becomes exponentially harder the larger the organization and the more applications it has. Two main challenges specifically stem from this; first, several factors will come into play an example being environmental factors (is the application exposed to the internet?) while the second challenge is the amount of labor that will need to be exerted to track down every application the organization is supporting (whether first/third party) and meet with the associated team that’s managing it. Meeting with the responsible teams has its own set of challenges particularly some being that the requirements document has been lost, some features have been understated while others having been exaggerated…
To combat some of the points discussed above, my team has been experimenting with various workflows. One of the workflows that we have found that currently works best is using software to map out the attack surface and then using the human approach to quickly categorize the risk the application poses. To map out the public attack surface, we have been leveraging the power of the Intrigue Core Engine. The Core Engine is a powerful beast as it will utilize different techniques to best map out the attack surface while also providing software fingerprints due in part to the robust application and service fingerprinting library known as Intrigue Ident. By fingerprinting the software, the Core Engine is then able to perform inferential vulnerability and misconfiguration checks based on the fingerprint returned by the software. This approach is stellar as it saves both time and tripping any wires that may alert the SOC team when compared to spraying and praying exploits. Throughout solidifying this workflow we have discovered several cues which help us to quickly categorize whether an application is worth further exploring or put it on the backburner.
Examples of such cues can include:
Please keep in mind that all the cues described below are accounting for the fact that the application is exposed to the Internet. While it is true that internal applications possess a risk, an attacker would require access by other means most likely by leveraging some form of exploitation in an exposed asset thus increasing the complexity required to exploit internal applications.
-
Whether or not the application is behind a login panel. If so, this may mean that the application possesses some form of information that requires an authorized party to view and at the very least has some form of attack surface with services talking to another one another (e.g DBMS, etc.)
-
If the software is provided by a third party and by which third party. This is a bit more subjective, however, if it’s a reputable vendor that’s known to take security seriously (such as by managing a bug bounty program, etc) there’s more confidence that it poses less risk compared to a smaller less reputable company.
Using these points along with the workflow described earlier is how the finding which will be described in the next section was discovered.
Finding
As mentioned, our organization runs a scan using Intrigue Core on a weekly basis. When reviewing the results, it was noticed that an asset that had an “Exposed Login Panel” was detected. While this by itself is not a vulnerability however citing the cues listed earlier, this did check off the two boxes (being exposed to the public + having a login panel). As this was discovered on a Friday afternoon right before a three-day weekend, chasing down the team responsible for managing this application would have been out of the question.
To provide some context regarding the application to make the rest of this section easier to understand. The application which will be shown is known as the EECP aka Energy Efficiency Collaboration Platform. This application is developed and managed by DirectTechnology. The premise behind the application is to provide energy companies a ‘platform’ in which they could collaborate with independent local contractors that will be contracted out to perform essential maintenance tasks for the energy company’s customers. Within this platform, the contractor is provided an account where they can be assigned jobs and have the ability to create invoices that will be charged to the energy company. Furthermore anytime a job is performed for a customer, the customer’s information is saved to the platform. This information will include the customer’s personal information such as their full name, address, email, account number, etc. However, it may also include more detailed information about the customer’s residence such as the type of stove they have (gas/electrical).
Poking around on the application, firing a request to any arbitrary path would have the application respond with a redirect bouncing the user back to the login panel. Some paths such as the directories which held static files were not redirected however, they did not yield any fruitful results. Eventually while iterating through wordlists, a directory was discovered that would not be met with a redirect which was /onlineapp.
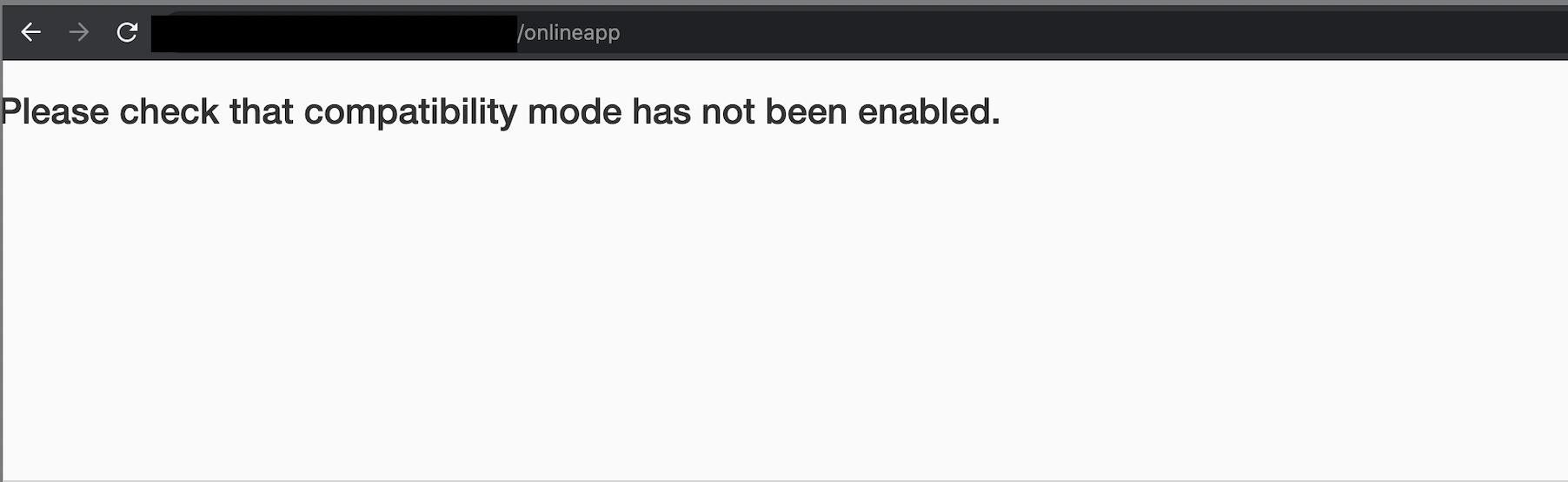
As shown in the screenshot above, the response would return a page that contained the following text:
Please check that compatibility mode has not been enabled.
At first thinking this was referring to Internet Explorer’s compatibility mode, Internet Explorer was used to browse to the path and the same result was returned.
Additional directory bruteforcing returned that home was a valid route. Browsing to /onlineapp/home now instead returned:
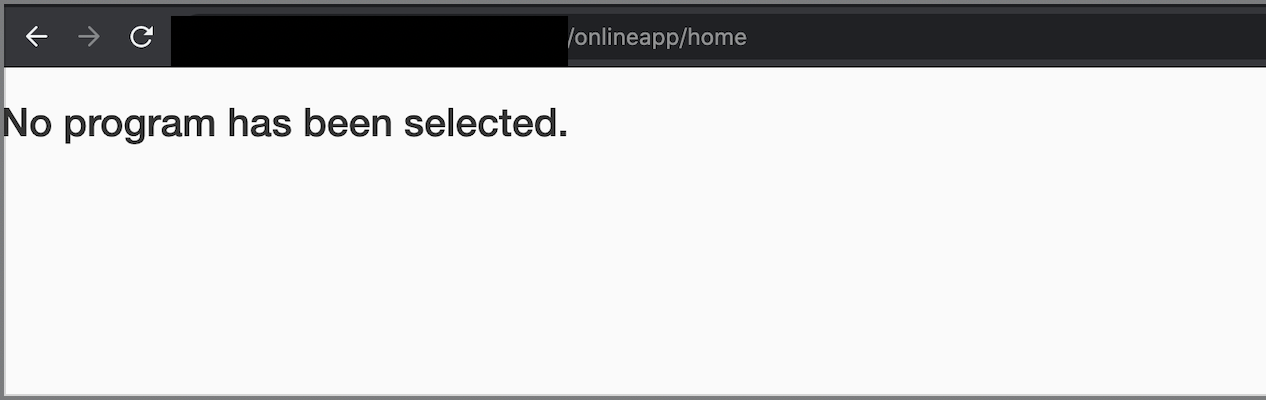
With a different response returned, the page was examined more closely and it was discovered that it was sourcing a fair amount of Javascript. This was done by viewing the Sources in the Chrome DevTools:
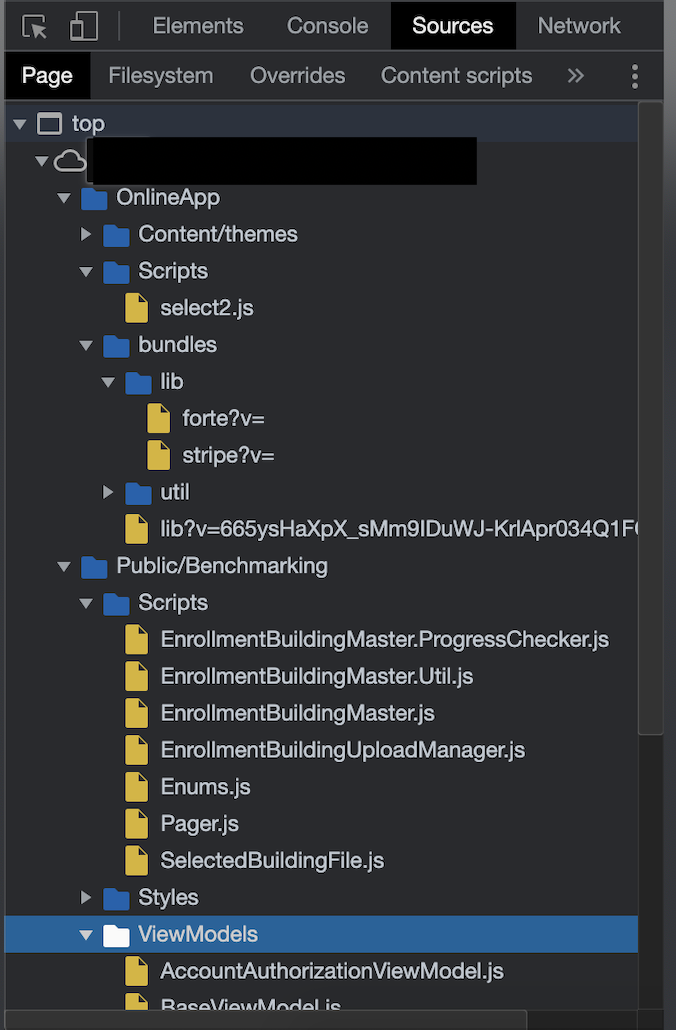
There were your typical third-party dependencies such as select.js however there were more scripts that appeared to be proprietary to the application. Further examining these scripts it was revealed that the application’s frontend is powered by Knockout.js which is a framework that promotes the Model-View-ViewModel pattern.
The Javascript was then dug through to find any endpoints to yield a larger attack surface. Especially as it was seen that the application was frontend heavy there was hope that maybe a route can be found that would return information about a program. After further investigation, there were several variations of endpoints being invoked by the Javascript found. These included your typical AJAX calls, either directly or the route being passed to a function that would fire off the request.
Furthermore what was more interesting is that a lot of these routes started with anchor # tags meaning they would not reach the server-side but rather intended for the frontend as the client-side router would pick it up.
Here is an example of a snippet:
if (currentlocation.indexOf("workflowstep") > 0 || currentlocation.indexOf("etoken") > 0 || currentlocation.indexOf("statuscheck") > 0) {
targetUrl = "#status/statuscheck?programId=" + AppState().data.vars["programId"];
}
else {
targetUrl = "#enrollment/?programId=" + AppState().data.vars["programId"];
}
Writing a quick Go script that would parse all the Javascript looking for matches that followed the pattern #anchor/path/ yielded the following results:
#status/statuscheck?programId=
#enrollment/?programId=
#enrollment/default?programId=
#enrollment/customerinformation?programId=
#workflowstep/installationresults?programId=
#enrollment/customerinformation?programId=
#workflowstep/installationresults?programId=
Attempting to load the first route, this resulted in the frontend making a request to load the content of /onlineapp/Content/ui/en-us/status/_master.htm?_=1632279783447 as it was shown in the Network tab of the Chrome DevTools.
For the sake of brevity purposes, the static page which was loaded had its own Javascript embedded which was invoking an additional API call to a route that would return whether a Program ID was valid or not. By examining the Javascript and constructing a valid API call, valid Program Ids were then discovered as they followed a sequential order. Using these Program Ids and additional routes discovered in the application, it was possible to leak the name of employees and contractors. Information such as the employee’s name, email, title, and phone number were discovered however after speaking with the vendor they confirmed that this was intended as the application administrator can toggle a feature that would disable this information from being returned. However, due to this being intended, this will not be explored within this post.
With the knowledge of the /onlineapp/Content/ui/en-us/status directory, a quick directory bruteforce was ran using the quickhits.txt wordlist which returned a surprising finding…
Note: This path could have been discovered by recursive directory bruteforcing. However, the sections regarding the Javascript were included to show how it was originally discovered
-
elmah.axd [Status: 200, Size: 31290, Words: 1398, Lines: 529]
-
elmah.axd returned a 200 valid status code. At first, it was thought that this may be the result of some WAF however when browsing to the path, the following was shown:
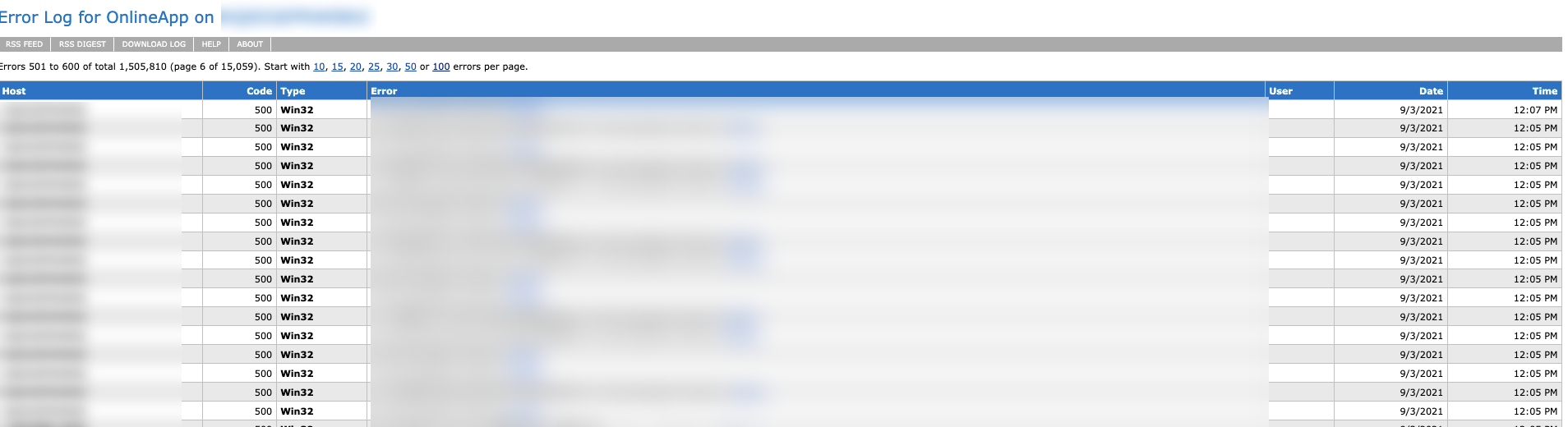
elmah.axd is essentially trace.axd's younger sibling. Unlike trace.axd which logs every request made to the application, elmah.axd only logs those which cause the application to throw an error. However just like trace.axd, elmah.axd logs the raw HTTP request which includes any session cookies. Both trace.axd and elmah.axd are used for debugging ASP.NET applications. The interesting thing behind both is that remote access is disabled by default meaning that to view the logs you would need to be connecting from the local IP Address. To read more about how security works within elmah, check out this great resource.
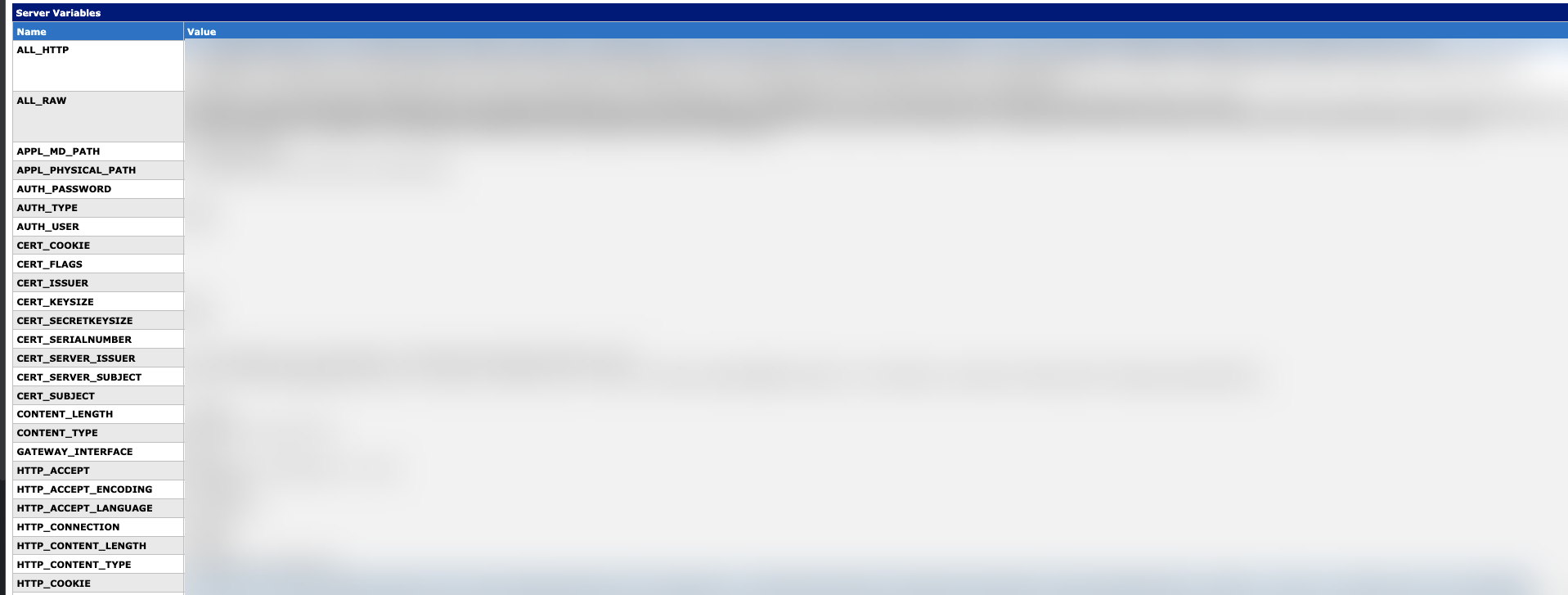
A snippet that displays helpful debugging information about the application including the contents of the HTTP request:
It was rather interesting that elmah.axd was discovered at this specific endpoint as access was forbidden in several other directories. The most likely reason behind this could be that this specific subdirectory may be a virtual directory that has its own web.config which was overriding the parent web.config that refused remote access to elmah.axd.
Session cookies found in the logs:

There may also be cases where the stack trace may contain sensitive information like customer info as shown below:
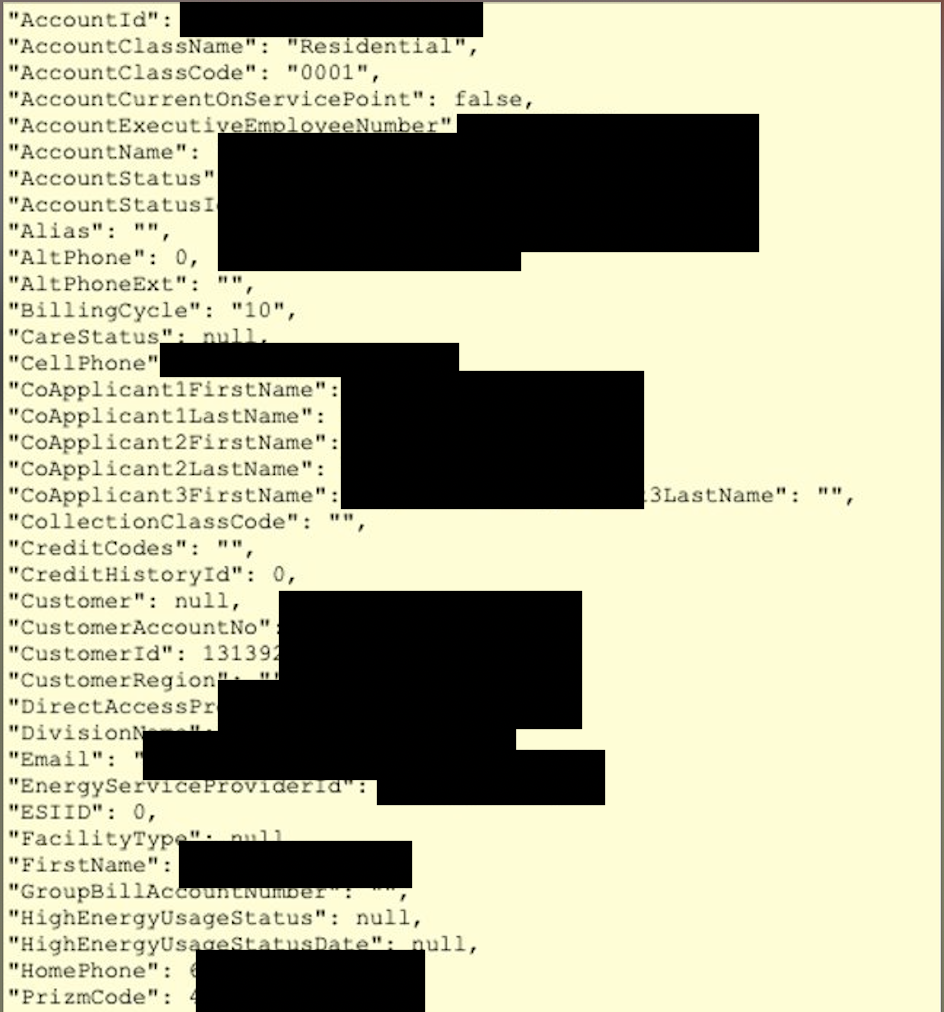
With the ability to obtain the session cookies, an attacker is now able to leverage session hijacking resulting in an authentication bypass.
Being able to access the portal as an authenticated user, an attacker can now:
-
Search & View Customer Information

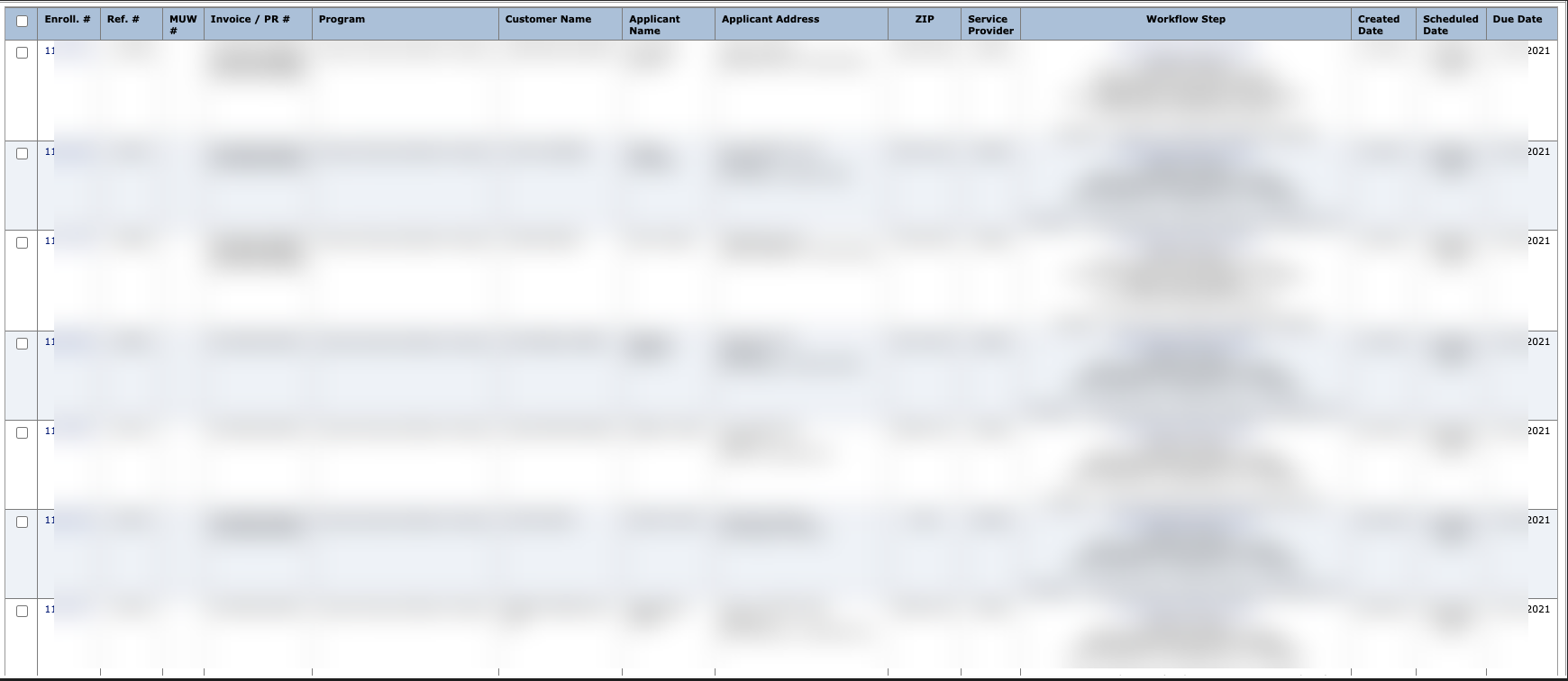
-
Submit Invoices on behalf of Employees
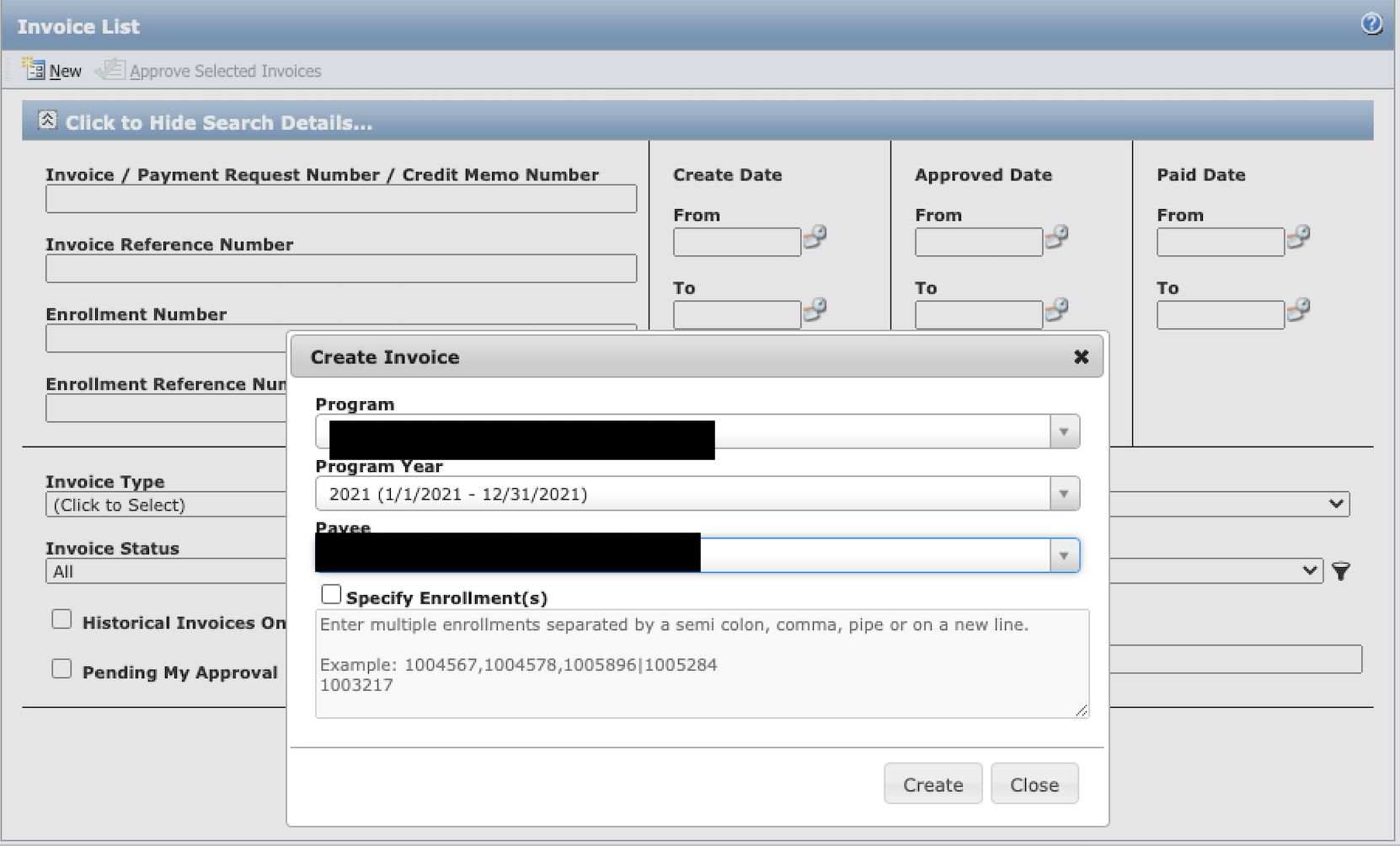
-
Access even a larger attack surface:

-
and much more…
Due to lack of time and the urgency of the authentication bypass, the engagement was halted and testing was shelved for later.
Vendor Response
Once it was discovered that an unauthenticated attacker would have the ability to access vast amounts of customer information and especially due to the policies and procedures an energy company is required to follow, it was decided that the application will need to be taken offline immediately and a meeting with the vendor (DirectTechnology) was arranged.
As the fix was minimal (adjusting the remote configuration settings of elmah.axd), the vendor was able to fix the issue literally within minutes during the call. Furthermore, they’ve mentioned that they will implement additional tests to prevent this sort of low-hanging fruit from regressing in the future.
The swift response from the vendor is greatly appreciated and deserves praise.
Affected Companies
Once the vulnerability was identified, it was decided next to discover whether any additional EECP instances were exposed to the internet. By employing a combination of passive techniques, it was found that there were several energy companies at risk.
These companies include:
- Hoosier Energy - Indiana
- Tampa Electric - Florida
- Cape Light Compact - Massachusetts
- MN Power - Minnesota
- SoCal Gas - California
- San Diego Gas & Electric - California
- Austin Energy - Texas
Conclusion
The goal behind this blog post was to discuss some of the challenges that large organizations face within appsec. Furthermore, some experimental solutions including a hybrid balance of automation and human effort while providing a real-world supporting example.
Thanks for reading.
© 2023 Ingredous Labs ― Powered by Jekyll and Textlog theme